Synchrone und asynchrone APIs
Was sie sind, worin die Unterschiede bestehen und wie man sie für eine effiziente und skalierbare Architektur nutzt

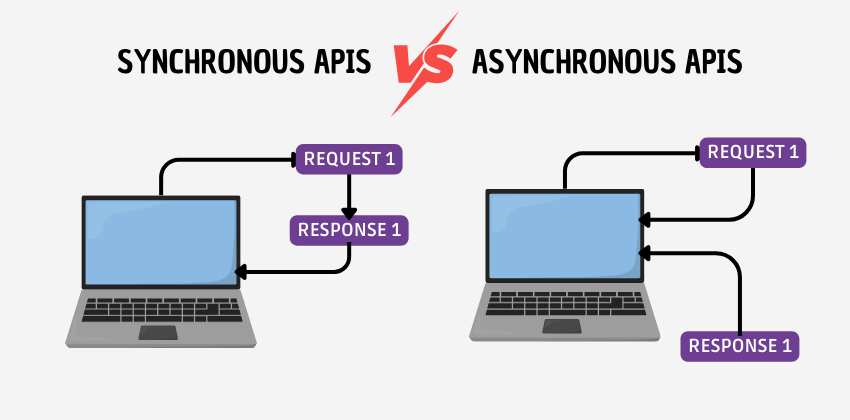
Die APIs (Application Programming Interface) funktionieren nach einem Request-Response-Modell: Bei einem API-Aufruf sendet der Client eine Anfrage an den Server, der anschließend die gewünschten Daten oder eine Nachricht zurückliefert. Dieses allgemeine Schema kann in zwei Ausführungsmodi umgesetzt werden: synchrone und asynchrone.
Die Unterscheidung zwischen diesen beiden Modellen ist nicht nur theoretischer Natur, sondern beeinflusst die Gestaltung skalierbarer und effizienter Systeme erheblich. Daher ist die korrekte Implementierung synchroner und asynchroner Interaktionsmechanismen ein grundlegendes Merkmal moderner Anwendungsarchitekturen.
Synchrone APIs: Was sie sind und wie sie funktionieren
In einer syncronen API erfolgt die Kommunikation in Echtzeit: Der Client sendet eine Anfrage an den Server und wartet, bis er eine Antwort erhält. Während dieser Zeit kann der Client keine weiteren Operationen ausführen oder neue Anfragen im selben Thread senden – daher spricht man von einem „blockierenden“ Mechanismus.
Dieser API-Typ ist ideal für schnelle Operationen wie das Abrufen von Geocoding-Daten für die Satellitennavigation oder das Aktualisieren einer gemeinsamen Datenbank. Die Serverantwort erfolgt nahezu sofort und enthält in der Regel die angeforderten Daten oder eine Bestätigung der ausgeführten Aktion, zum Beispiel das Löschen einer Ressource oder das Weiterleiten einer Nachricht.
Synchrone APIs sind sehr häufig in Web-Microservices, da sie sofortiges Feedback ermöglichen und leicht zu implementieren sind. Andererseits muss der Client bei diesem Kommunikationsmodell auf die Antwort des Servers warten, bevor er fortfahren kann. Das bedeutet, dass es nur geeignet ist, wenn die Verarbeitung der Antwort sehr wenig Zeit benötigt. In einigen Anwendungen – etwa beim Laden und Analysieren großer Videodateien oder bei der Erstellung eines Finanzberichts – kann dieser Mechanismus ineffizient werden und die Skalierbarkeit beeinträchtigen.
Was sind asynchrone APIs?
Im Gegensatz zu synchronen APIs arbeiten asynchrone APIs nach einem Request-Accept-Notify-Modell: Wenn der Client eine Anfrage sendet, bestätigt der Server, dass die Operation angenommen wurde. Der typische Antwortcode ist „202 Accepted“, und die Antwort enthält normalerweise auch eine ID, mit der das endgültige Ergebnis später abgerufen werden kann. Der Client kann in der Zwischenzeit andere Anfragen verarbeiten – ein „nicht blockierender“ Mechanismus.
Sobald der Server die Anfrage verarbeitet hat, sendet er die Antwort an den Client. Dies kann auf zwei Arten geschehen:
- Polling: Der Client fragt den Server in regelmäßigen Abständen ab, bis die Antwort verfügbar ist (Pull-Modell);
- Callback / Webhook: Sobald die Antwort fertig ist, ruft der Server eine URL des Clients auf, um ihn über den Abschluss der Operation zu informieren (Push-Modell).
Asynchrone APIs sind unverzichtbar in Szenarien mit langen Antwortzeiten, wie z. B. der Verarbeitung von Videos oder Dokumenten. Ihr Hauptvorteil ist die völlige Abwesenheit von Wartezeiten, die eine optimale Nutzung von Rechen- und Netzwerkressourcen ermöglicht. Allerdings sind asynchrone Abläufe komplexer einzurichten, da sie unter anderem die Verwaltung von Benachrichtigungen erfordern.
Die Unterschiede zwischen synchronen und asynchronen APIs
Zusammenfassend lassen sich die Unterschiede zwischen synchronen und asynchronen APIs wie folgt beschreiben:
- Arbeitsablauf: Synchrone APIs blockieren den Client, während auf die Antwort gewartet wird, während asynchrone APIs Referenzen liefern, um die Antwort später abzuholen, und den Client sofort freigeben;
- Anwendungsfälle: Synchrone APIs eignen sich für kurze, schnelle Vorgänge, während asynchrone APIs für alle Vorgänge bevorzugt werden, die mehr als ein paar Millisekunden dauern oder Arbeitswarteschlangen erfordern;
- Zustellung der Antwort: Bei synchronen APIs trifft die Antwort sofort ein, während sie bei asynchronen APIs über spätere Benachrichtigungsmechanismen erfolgt (Polling oder Callback);
- Komplexität: Asynchrone APIs sind komplexer zu implementieren, da sie den Status der Operation über die Zeit hinweg verwalten müssen und Benachrichtigungsmechanismen erfordern, die mit dem Client abgestimmt werden müssen (z. B. Polling-Zyklen oder ein Callback-Endpoint).
Viele moderne Anwendungen verwenden hybride Architekturen, in denen synchrone und asynchrone APIs je nach Bedarf kombiniert werden. In jedem E-Commerce-System nutzen Vorgänge wie Warenkorbprüfung und Zahlungsautorisierung synchrone Kommunikation, während nachgelagerte Vorgänge – wie Bestellbestätigungs-E-Mails und Rechnungserstellung – asynchron erfolgen.
Wann sollten synchrone und asynchrone APIs verwendet werden?
Die Entscheidung zwischen synchronen und asynchronen APIs hängt grundsätzlich von der Ausführungszeit der Operation und dem Bedarf nach einer sofortigen Antwort auf Clientseite ab. Wenn der Client die Antwort benötigt, bevor er fortfahren kann, ist synchrone Kommunikation sinnvoll. Typische Beispiele sind Authentifizierungsprozesse, bei denen der Server die Zugangsdaten sofort prüfen muss, sowie das Abrufen von Echtzeitdaten, etwa für das Laden von Bildern oder Produktmetadaten auf einer E-Commerce-Seite.
Asynchrone APIs sind unverzichtbar für jede Operation, deren Verarbeitung mehr als wenige Millisekunden dauert. Häufige Beispiele sind das Verarbeiten großer Dateien, deren Konvertierung oder Import im Hintergrund erfolgen kann, während der Client andere Aufgaben ausführt, oder das Versenden großer Mengen an E-Mails, das sofort angenommen und im Laufe der Zeit abgearbeitet wird.
Wenn die Verarbeitung im Hintergrund erfolgen kann, ohne den Client zu blockieren, und keine sofortige Rückmeldung erforderlich ist, ist eine asynchrone Architektur die effizienteste Wahl – insbesondere in Umgebungen mit hoher Ressourcennutzung, wie z. B. Börsenhandelsplattformen, bei denen die Aggregation historischer Daten Zeit benötigt, aber die Echtzeit-Operationen nicht blockieren darf.
VERWANDTE ARTIKEL
Kohlenstofffreie Energie für unsere Cloud ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Gesellschaft unter der Leitung und Kontrolle der Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Rom - Handelsregister REA 1378273 - Stammkapital € 50.000,00 eingezahlt – MwSt.-Nr. IT12485671007 - Empfängercode 'USAL8PV' - PEC: 
Openapi ist zertifiziert: Qualitätsmanagementsystem UNI EN ISO 9001:2015 - Datenqualität ISO 25012:2014 - Sicherheitsmanagement ISO/IEC 27001:2022 - Geschlechtergleichstellung gemäß UNI PdR 125:2022
Alle Preise verstehen sich zuzüglich eventueller MwSt., eventuell anfallender Stempelsteuern, Registrierungsgebühren und/oder sonstiger Steuern oder Abgaben, sofern diese fällig sind. Alle auf dem Portal aufgeführten Logos sind urheberrechtlich geschützt und Eigentum der jeweiligen Inhaber.








