Was ist das TOON-Format (Token-Oriented Object Notation)
Wie TOON (Token-Oriented Object Notation) funktioniert, das kompakte Datenformat, das die Anzahl der Tokens in KI-Prompts im Vergleich zu JSON um bis zu 60 % reduziert.

Inhaltsverzeichnis
- Wie TOON die Art verändern kann, wie KI Daten „sieht“
- Warum TOON gerade jetzt wichtig ist
- Was TOON ist: Definition und Grundprinzipien
- Wie das TOON-Format funktioniert
- Wie TOON funktioniert (für Nicht-Programmierer)
- Welche Vorteile bietet TOON?
- Wann TOON besonders nützlich ist
- Wann man kein TOON verwenden sollte
- Wie TOON in LLM-Prompts verwendet wird
- Einfache Tools für den Einsatz von TOON
- Aktueller Projektstatus und Roadmap
- Kritische Punkte und Vorsicht: Was noch nicht bestätigt ist
Wie TOON die Art verändern kann, wie KI Daten „sieht“
In der Welt der modernen künstlichen Intelligenz, insbesondere beim Einsatz großer Sprachmodelle (Large Language Models, LLM), gilt: Jeder Token zählt. Die Kosten einer API sowie Latenz und Effizienz des Prompts hängen direkt davon ab, wie viele Token an das Modell gesendet werden. In diesem Kontext entsteht TOON (Token-Oriented Object Notation), ein kompaktes, gut lesbares Serialisierungsformat, das speziell dafür entwickelt wurde, die Anzahl der benötigten Token bei der Darstellung strukturierter Daten zu minimieren.
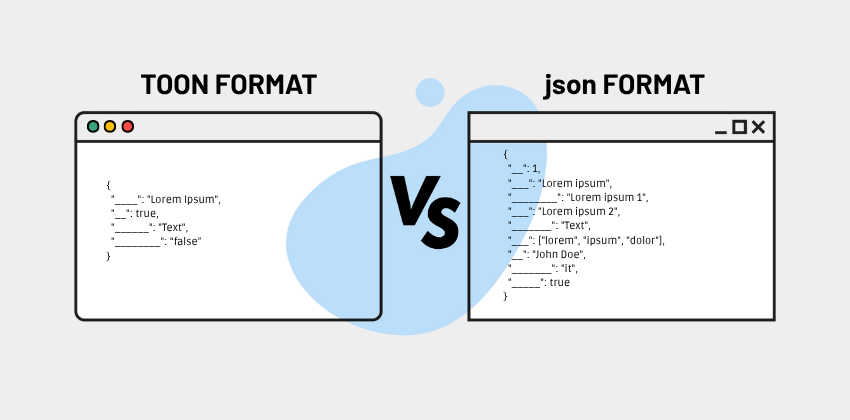
Anstatt das klassische JSON-Format (oder andere) zu verwenden, „verpackt“ TOON dieselben Informationen auf eine schlankere und optimierte Weise – und bleibt dabei dennoch gut für Menschen lesbar.
Schauen wir uns im Detail an, was TOON ist, warum es nützlich ist, wie es funktioniert, seine Grenzen und den aktuellen Entwicklungsstand.
Warum TOON gerade jetzt wichtig ist
Das Problem mit JSON in KI-Workflows
JSON wird häufig verwendet, um strukturierte Daten darzustellen. Aber es hat eine „wortreiche“ Grammatik: geschweifte Klammern { }, eckige Klammern [ ], Anführungszeichen ", Kommata, Einrückungen … all dies erzeugt zusätzliche Token, wenn Payloads an ein LLM gesendet werden.
Wenn viele gleichförmige Objekte vorhanden sind (z. B. eine Liste von Nutzern, Produkten oder Datensätzen), wiederholen sich die Schlüssel ständig, was den Tokenverbrauch weiter erhöht.
Die Lösung? TOON!
TOON wurde genau entwickelt, um dieses Problem zu lösen: Es ist ein Format, das auf maximale Token-Effizienz ausgelegt ist und dennoch menschliche Lesbarkeit und die vollständige semantische Struktur von JSON beibehält. Laut verschiedenen Benchmarks kann TOON den Tokenverbrauch gegenüber klassischem JSON um 30–60 % reduzieren. Diese Reduktion führt zu geringeren API-Kosten, mehr verfügbarem Kontextfenster und in einigen Fällen sogar zu höherer Genauigkeit bei der Dateninterpretation durch LLMs.
Auch bei Openapi arbeiten wir in diese Richtung, und schon in den kommenden Wochen werden unsere APIs das neue Format unterstützen.
Was TOON ist: Definition und Grundprinzipien
TOON ist die Abkürzung für Token-Oriented Object Notation. Es handelt sich um ein textbasiertes Serialisierungsformat für strukturierte Daten, das speziell für die Übergabe an LLMs entwickelt wurde. TOON ist:
- Kompakt und token-effizient: eliminiert viele redundante syntaktische Elemente von JSON.
- Schema-aware: nutzt explizite Längenangaben von Arrays und Feldern, um die Struktur formaler zu gestalten.
- Menschlich lesbar: bleibt dank YAML-ähnlicher Einrückung gut lesbar.
- Tabellarisch für uniforme Arrays: bei Arrays, in denen alle Objekte dieselben Felder haben, nutzt TOON eine Tabellenstruktur (Header + Zeilen), die an CSV erinnert.
Laut dem offiziellen GitHub-Repository ist TOON verlustfrei gegenüber JSON: Daten können ohne Informationsverlust zwischen JSON → TOON → JSON konvertiert werden.
Wie das TOON-Format funktioniert
Grundsyntax
1. Einfache Objekte
TOON entfernt geschweifte Klammern und verwendet Einrückungen für die Verschachtelung.
Beispiel:
id: 123 name: Ada active: true Dies entspricht dem JSON-Objekt
{ "id": 123, "name": "Ada", "active": true }2. Verschachtelte Objekte
Mit YAML-ähnlicher Einrückung:
user: id: 123 name: AdaJSON-Darstellung:
{ "user": { "id": 123, "name": "Ada" } } 3. Arrays primitiver Werte („primitive array“)
TOON deklariert Länge und Werte inline:
tags[3]: foo,bar,baz Dies entspricht
["foo", "bar", "baz"] in JSON.
4. Arrays uniformer Objekte (tabellarisches Array)
Dies ist der token-effizienteste Teil:
users[2]{id,name,role}: 1,Alice,admin 2,Bob,user - users[2]: zeigt ein Array mit 2 Elementen an
- {id,name,role}: die Schlüssel (Felder), die jedes Objekt besitzt
Die folgenden Zeilen enthalten die Werte, durch Kommas getrennt, jeweils eine Zeile pro Objekt.
5. Delimiter-Optionen
Für die Trennung der Werte in Zeilen unterstützt TOON verschiedene Delimiter: Komma (,), Tabulator (\t) oder Pipe (|). Der Einsatz von Tab oder Pipe kann weitere Token sparen, da weniger Quoting nötig ist.
6. Key Folding (Schlüssel-Faltung)
Die TOON-Spezifikation sieht optionales „Key Folding“ vor: Wenn Strukturen nur eine einzige Schlüsselhierarchie haben („Wrapper“ mit nur einem Schlüssel), können diese durch Punktnotation kompakter dargestellt werden.
7. Quoting von Strings
Strings werden in TOON nur gequotet, wenn notwendig: z. B. wenn sie den verwendeten Delimiter, einen Doppelpunkt :, führende/folgende Leerzeichen oder Steuerzeichen enthalten.
8. Konvertierung spezieller Typen
- Zahlen: im Dezimalformat (nicht in wissenschaftlicher Notation).
- NaN oder ± Infinity werden zu null.
- BigInt: innerhalb des sicheren Bereichs als Zahl, sonst als gequotete dezimale Zeichenkette.
- Datum: als ISO-String gequotet.
- Nicht serialisierbare Werte werden typischerweise zu null.
Wie TOON funktioniert (für Nicht-Programmierer)
Für Personen ohne Entwicklerhintergrund lässt sich TOON als eine „schlankere Sprache“ zur Beschreibung von Daten verstehen.
Wenn eine Gruppe ähnlicher Elemente übermittelt werden muss (z. B. eine Liste von Nutzern, alle mit Name, Alter, Rolle), ermöglicht TOON, dass man einmal die Felder (Name, Alter, Rolle) deklariert und anschließend Zeile für Zeile die Werte angibt. Dadurch müssen die Felder nicht ständig wiederholt werden, wie es bei klassischem JSON der Fall ist – das spart „Treibstoff“ (Token). Bei einfachen Daten (z. B. einer reinen Liste von Tags) stellt TOON alles kompakt dar: weniger Symbole, weniger „unnötige Satzzeichen“. Bei verschachtelten Daten (z. B. ein Objekt in einem anderen) nutzt TOON Einrückungen (also Leerzeichen), um Hierarchie darzustellen – ähnlich wie in einem gut strukturierten Dokument, aber ohne schwere Klammern.
Kurz: TOON behält die logische Struktur der Daten bei, reduziert jedoch die „leeren Wörter“.
Welche Vorteile bietet TOON?
Die Vorteile des TOON-Formats im Überblick:
1. Token-Effizienz
Dank minimalistischer Syntax, einmaliger Schlüsseldefinition und tabellarischer Struktur ermöglicht TOON eine durchschnittliche Einsparung von 30–60 % der Token im Vergleich zu JSON. Das ist besonders relevant in LLM-Workflows mit vielen repetitiven, tabellarischen Daten.
2. Höhere Genauigkeit (schema-aware Guardrails)
TOON ist nicht nur kompakt, sondern auch schema-aware. Die Deklaration der Array-Länge ([N]) und der Felder ({…}) hilft LLMs, die Struktur besser zu validieren, wodurch Fehler, Auslassungen oder „Halluzinationen“ reduziert werden. Benchmarks zeigen, dass TOON eine höhere Retrieval-Genauigkeit erzielen kann als kompaktes JSON.
3. Menschliche Lesbarkeit
Trotz der Reduktion an Symbolen bleibt TOON für Entwickler gut lesbar – dank Einrückung, tabellarischer Anordnung und klarer Syntax. Das erleichtert Debugging, manuelles Prompting und die Analyse durch Prompt Engineers.
4. Kompatibilität und vollständige Informationsbewahrung
TOON ist JSON-verlustfrei: Jede JSON-Struktur kann in TOON dargestellt und ohne Informationsverlust zurückkonvertiert werden. Es existieren Bibliotheken und SDKs für Encoding (encode) und Decoding (decode) in verschiedenen Sprachen (z. B. TypeScript, Elixir, PHP).
5. Sprachübergreifende Implementierungen
TOON ist nicht nur ein theoretisches Konzept: Es existieren konkrete Implementierungen in vielen Sprachen:
- TypeScript / JavaScript: offizielles SDK im Hauptrepository
- Elixir: TOON-Implementierung für Elixir
- PHP: TOON-Portierung für PHP
- R: CRAN-Paket zur Serialisierung von R-Objekten in TOON
Weitere Sprachen folgen dank der offenen Spezifikation.
Wann TOON besonders nützlich ist
TOON bietet seine größten Vorteile in typischen Anwendungsfällen:
- Listen ähnlicher Elemente: Wenn viele Objekte dieselben Felder haben (z. B. Nutzer, Bestellungen, Produkte), sind die Einsparungen am größten.
- Prompts für KI: Bei der Übergabe strukturierter Daten an ein Modell hilft TOON bei besserer Interpretation bei geringerem Overhead.
- Szenarien, bei denen Tokenkosten wichtig sind: Wenn pro Token bezahlt wird, kann TOON die Kosten deutlich reduzieren.
- Debugging oder lesbare Datenbearbeitung: Dank guter Lesbarkeit sind Daten in TOON verständlicher als stark minimiertes JSON.
Wann man kein TOON verwenden sollte
TOON ist nicht immer die ideale Wahl. Es gibt Fälle, in denen andere Formate effizienter sein können:
- Sehr stark verschachtelte oder nicht uniforme Strukturen Wenn viele Ebenen von Verschachtelungen vorhanden sind oder Arrays unterschiedlich strukturierte Objekte enthalten, kann die Tokenersparnis sinken oder schlechter als bei kompaktem JSON sein.
- Rein tabellarische, einfache Daten Bei flachen Tabellen ohne Verschachtelung kann CSV kompakter sein, da TOON Metadaten wie Längen- und Felddeklarationen hinzufügt.
- Latenzkritische Anwendungen Wenn Serialisierungs- und Deserialisierungszeit wichtiger ist als Tokenverbrauch, kann kompaktes JSON schneller sein, auch wenn es mehr Token verwendet.
Wie TOON in LLM-Prompts verwendet wird
Encoding vor dem Senden
Offizielle Bibliotheken können zur Konvertierung von JSON-Objekten in TOON verwendet werden, z. B. das offizielle TypeScript-Paket (@toon-format/toon)
Beim Erstellen des Prompts kann das serialisierte TOON in einem Codeblock platziert werden, z. B.:
toon users[3]{id,name,role}: 1,Alice,admin 2,Bob,user 3,Charlie,user Dies hilft dem Modell, die Struktur zu erkennen und konsistent zu antworten.
Generierung von TOON durch das LLM
Wenn das Modell Daten im TOON-Format erzeugen soll:
- Ein TOON-Header-Beispiel zeigen (wie users[N]{…}:)
- Angeben, dass das Modell die entsprechenden Zeilen und die korrekte Zahl [N] liefern soll
- Verlangen, dass die Antwort ausschließlich im Codeblock und im TOON-Format erfolgt
Dieses Vorgehen ist effektiv, da das Modell die Schlüsselnamen nicht wiederholt „erraten“ muss: Sie sind bereits deklariert.
Einfache Tools für den Einsatz von TOON
Man muss kein Experte sein, um TOON auszuprobieren. Es gibt Tools für Personen mit Daten, die keinen komplexen Code schreiben möchten:
- Web-Konverter: Websites, auf denen man Daten (z. B. JSON oder CSV) einfügen und automatisch die optimierte TOON-Version erhalten kann – direkt im Browser.
- Interaktive Playgrounds: Einige Tools zeigen in Echtzeit, wie viele Token das Format benötigt – ideal, um Einsparungen zu bewerten.
- Sichere Tools: Clientseitige Anwendungen (die im Browser laufen) konvertieren Daten, ohne sie an externe Server zu senden – für mehr Datenschutz.
Aktueller Projektstatus und Roadmap
Das Projekt TOON ist aktiv und open-source. Das offizielle GitHub-Repository enthält Spezifikation, Code und Benchmarks. Die offizielle Spezifikation befindet sich in Version 2.0 (Working Draft). Es gibt bereits Implementierungen in vielen Sprachen (TypeScript, Elixir, PHP, R usw.) und weitere werden folgen. Es existieren Web-Tools und Converter (z. B. ToonParse) zur clientseitigen JSON → TOON- und TOON → JSON-Konvertierung. Benchmarks zeigen, dass TOON nicht nur Token reduziert, sondern auch die Retrieval-Genauigkeit bei strukturierten Daten verbessern kann.
Kritische Punkte und Vorsicht: Was noch nicht bestätigt ist
Wie einige Community-Kommentare hervorheben, wurden viele LLMs nicht explizit auf TOON „trainiert“: Die Trainingsdaten bestanden vermutlich fast vollständig aus JSON oder anderen Formaten. Daher kann die Nutzung von TOON Anpassungen erfordern, und in manchen Fällen reagiert das Modell weniger optimal, wenn es mit der Struktur nicht vertraut ist. Obwohl TOON open-source und schnell wachsend ist, ist es noch relativ neu. Die Spezifikation entwickelt sich weiter, daher können einige Implementierungen inkompatibel sein, wenn nicht dieselbe Version genutzt wird.
Fazit (oder kurz gesagt)
TOON (Token-Oriented Object Notation) stellt eine bedeutende Innovation in der Datenserialisierung für LLM-Anwendungen dar. Dank seiner kompakten, gut lesbaren und schema-aware Struktur ermöglicht es eine drastische Reduktion des Tokenverbrauchs gegenüber traditionellem JSON (oft bis zu 60 %) – ohne semantische Verluste.
Dennoch ist Realismus wichtig: Nicht alle Szenarien eignen sich bereits für TOON. Derzeit ist TOON ein ergänzendes Werkzeug zu JSON – sinnvoll, wenn Token-Einsparungen wirtschaftliche oder technische Vorteile bringen, aber noch kein universeller Ersatz.
Wenn du als Entwickler mit LLMs arbeitest, lohnt sich ein Blick auf TOON: Es hilft, effizientere Prompts zu bauen, API-Kosten zu optimieren und das Kontextfenster besser zu nutzen. Gleichzeitig sollte ein pragmatischer Ansatz beibehalten werden: Vorteile im eigenen Use Case messen und die Zuverlässigkeit der JSON ↔ TOON-Konvertierung testen.
Openapi wird bald TOON in seinen APIs unterstützen – eine sehr wichtige Neuerung. Anwendungen, die diese APIs nutzen, können dadurch effizienter und kostengünstiger werden und ein modernes, optimiertes Format verwenden.
VERWANDTE ARTIKEL
Kohlenstofffreie Energie für unsere Cloud ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Gesellschaft unter der Leitung und Kontrolle der Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Rom - Handelsregister REA 1378273 - Stammkapital € 50.000,00 eingezahlt – MwSt.-Nr. IT12485671007 - Empfängercode 'USAL8PV' - PEC: 
Openapi ist zertifiziert: Qualitätsmanagementsystem UNI EN ISO 9001:2015 - Datenqualität ISO 25012:2014 - Sicherheitsmanagement ISO/IEC 27001:2022 - Geschlechtergleichstellung gemäß UNI PdR 125:2022
Alle Preise verstehen sich zuzüglich eventueller MwSt., eventuell anfallender Stempelsteuern, Registrierungsgebühren und/oder sonstiger Steuern oder Abgaben, sofern diese fällig sind. Alle auf dem Portal aufgeführten Logos sind urheberrechtlich geschützt und Eigentum der jeweiligen Inhaber.








